Mayo Clinic researchers and collaborators have shown that an artificial intelligence (AI) tool can analyse routine pathology slides to help clinicians classify meningiomas, the most common primary brain tumour in adults, and better understand a patient’s risk of tumour recurrence.
The study, published in The Lancet Digital Health, demonstrates that deep learning models can support the extraction of molecular and prognostic information from standard haematoxylin and eosin, or H&E, slides – the same type of tissue images already used in routine clinical care. These insights are typically obtained through DNA methylation profiling, an advanced genetic test which provides valuable diagnostic and prognostic information but can be costly, time-consuming and is unavailable in many hospitals.
“This is one of the many studies where we can harness the strength of digital pathology by capturing the last two decades of genomic and molecular knowledge into AI algorithms,” says Gelareh Zadeh, MD, PhD, chair of the Department of Neurologic Surgery at Mayo Clinic in Rochester and Chief Medical Officer for Mayo Clinic Platform.
Making advanced tumor insights more accessible
Meningiomas can vary widely in behaviour. Some grow slowly and may never return after treatment, while others are more aggressive and more likely to recur. Understanding that risk is critical for patients and care teams deciding whether additional treatment, such as radiation therapy, may be needed after surgery.
Molecular testing can help identify which tumours are more likely to recur and which may respond differently to treatment. But these tests require specialized technology and expertise, limiting access for many patients.
Using tissue samples, pathology images and clinical data from 672 patients, researchers developed and tested AI models designed to help identify patterns linked to a tumour’s biology. Drawing on multiple de-identified datasets, including data resources from Mayo Clinic Platform, the models supported classification of meningioma subtypes and recurrence risk prediction using standard pathology slides that are already part of routine patient care.
The findings suggest that, with further validation, AI-based tools could one day help clinicians obtain more detailed tumour information to inform patient care, without requiring every patient to undergo advanced genetic testing.
Helping guide treatment decisions
For patients with meningiomas, recurrence risk can influence follow-up care, imaging frequency and whether radiation therapy should be considered. The study found that AI-based predictions remained useful even after accounting for traditional clinical factors such as tumour grade, the extent to which surgery was able to remove the tumour and patient age.
Researchers also found that the AI models could identify patterns of tumour heterogeneity – differences within the same tumour – that may help explain why some tumours behave more aggressively or respond differently to treatment.
The researchers note that additional prospective studies are needed before the AI models can be used routinely in clinical care. Still, they say the findings lay the groundwork for more accessible, personalised care for patients with meningiomas – and potentially for similar AI approaches in other cancers.
As with any clinical decision-support tool, the researchers emphasise that these models would require rigorous evaluation, validation and ongoing physician oversight before being considered for routine care. “The aim is to make these algorithms readily and simply accessible for use globally, improving patient care across many healthcare settings,” says Dr Zadeh.
For a complete list of authors, disclosures and funding, review the publication.
By Vishal Barapatre, Group Chief Technology Officer at In2IT Technologies
| 17 June 2026
Healthcare is investing heavily in technology, but outcomes do not always improve at the same rate or deliver the desired effect. The issue is rarely a lack of tools. More often, it comes down to the way those tools are designed, connected, and maintained. Health technology, often referred to as Healthtech, delivers real value not just when systems exist, but also when expert IT partners shape them to turn health data into meaningful, useful intelligence throughout the entire care journey.
In many healthcare environments, technology has accelerated rapidly over the past decade. Hospitals and clinics have introduced electronic medical records, diagnostic platforms, and telehealth systems, with enormous potential, the benefits are often uneven when systems operate in isolation or fail to align with the realities of clinical workflows. The difference between technology investment and measurable clinical improvement often lies in the design and integration that happens behind the scenes.
The promise of healthtech lives in the data
At its core, healthtech is about data. This includes how data is captured, stored, presented, and analysed to support better patient care. Every interaction between a patient and the healthcare system generates information that can guide more informed decisions. From recognising early signals for preventive care, tracking progress during rehabilitation, to ensuring complete and accurate information during operative procedures, effective use of data underpins every stage of the healthcare journey.
Yet data alone is not enough. Without systems designed to bring clarity to complexity, information becomes fragmented, inconsistent, and largely underused. This is where expert IT partners are essential. They do not just implement platforms; they create the right conditions for data to support better patient care.
Another challenge lies in the diversity of healthcare data sources. Clinical records, laboratory results, imaging systems, wearable devices, and patient engagement platforms, all generate valuable information. However, without thoughtful integration and governance, these data streams can quickly become disconnected. When aligned, they allow clinicians to see a more complete picture of a patient’s health, enabling earlier intervention and more personalised treatment decisions.
Intuition does not happen by accident
There is a growing expectation that healthtech should feel intuitive, where insights emerge naturally without creating additional friction in already demanding clinical environments. However, intuitive technology does not happen by chance. It results from thoughtful choices about structure, integration, and user experience.
What needs to be understood is that a system’s value is not determined by its technical features but by how well it fits into clinical workflows. The data must be available at the right time, in the right context, and in a way that supports judgment instead of overwhelming it. Without this insight and expertise, even the most advanced systems may become obstacles instead of assets.
This is particularly important in high-pressure healthcare environments where time is limited, and decisions are critical. If systems require excessive navigation, duplicate data entry, or complicated interfaces, clinicians may spend more time interacting with technology than with the patients. Well-designed systems quietly support decision-making rather than compete for attention, ensuring that technology strengthens clinical practice of disrupting it.
Continuity of care requires continuity of systems
To add, preventive, rehabilitative, and operative care are often treated as separate areas, yet they are part of a single patient journey. The true value of healthtech emerges when data flows smoothly across these stages, creating continuity instead of hand-offs.
This continuity does not happen on its own. It relies on systems that preserve data integrity over time, integrate seamlessly across different care settings, and evolve as patient needs evolve. Without it, technology investments risk becoming isolated solutions rather than truly transformative tools.
When healthcare providers can access consistent patient information across departments and care phases, they gain a more holistic understanding of health outcomes. This continuity helps reduce redundant tests, prevent information gaps, and support coordinated treatment plans. Over time, it contributes to a healthcare environment where patients’ experiences feel more connected and less fragmented.
Trust is built behind the scenes
To truly be transformative, healthcare must rely on trust between patients and clinicians, as well as between clinicians and the systems they depend on. Yet, this trust is fragile, as a single system failure, data inconsistency, or security issue can erode confidence across a healthcare facility.
Trust is built on reliability, resilience, and strong governance. Systems must perform well under pressure, safeguard sensitive information, and evolve safely over time. Although this foundation work often goes unnoticed, its impact is felt every time clinicians use technology with confidence and ease.
The growing digitisation of healthcare has also made cybersecurity and data protection essential pillars of trust. Healthcare data is among the most sensitive information an organisation can manage. Protecting it requires robust security architecture, continuous monitoring, and governance practices that evolve as threats emerge. When these safeguards are embedded into the system architecture, healthcare organisations can innovate confidently without compromising patient privacy.
The real differentiator is partnership, not platforms
As healthtech continues to evolve, access to tools will be less of a significant differentiator. What will matter more is how those tools are shaped, connected, and sustained. Technology alone cannot provide better care. It requires partners who understand both the technical and human aspects of healthcare.
This is where an IT partner can navigate and guide healthcare organisations through complexity, turning possibilities into practice and ambitions into results. Their role is not just supportive but foundational in demonstrating the true value of healthtech. The future of healthcare will belong not to those who adopt the most technology, but to those who build it wisely.
Nine leading AI models were tested on simple administrative queries drawn from real-world emergency department records—and most failed unless paired with code-generation tools.
A new study finds that large language models (LLMs), used with straightforward prompting, perform poorly on routine number-crunching tasks that hospital administrators depend on every day to track patients and allocate resources. The findings were published this week in the open-access journal PLOS Digital Health by Eyal Klang of the Icahn School of Medicine at Mount Sinai, New York, USA, and colleagues.
Hospitals rely on structured electronic health record (EHR) data to monitor patient counts and resources and to generate administrative reports. These tasks are currently handled by data analysts using programming languages, creating delays when staff need fast answers. AI tools known as large language models, such as GPT-4o and Llama, have been proposed to simplify that process.
In the new study, researchers evaluated nine leading LLMs on two basic administrative tasks—counting patients meeting a condition and filtering records based on multiple criteria—using data drawn from 50 000 real emergency department visits at the Mount Sinai Health System.
The researchers found that straightforward prompting—asking the model a plain question like “how many patients in this table were admitted?”—produced uniformly poor results across all models. Chain-of-thought reasoning, in which the model is prompted to show step-by-step work before giving an answer, offered only modest improvements that degraded sharply as table size increased. Even GPT-4o, the top-performing model, saw accuracy drop from roughly 95% on the smallest datasets to below 60% on larger ones under chain-of-thought conditions.
A tool-based approach—where models were asked to generate code that was then executed—substantially improved accuracy for the most capable models, with GPT-4o and Qwen-2.5-72B achieving near-perfect performance. However, distilled DeepSeek models, optimised for speed and efficiency, struggled even with this approach. One model, Llama-3.1-8B, failed to produce usable output in the majority of trials and was excluded from further analysis.
“Our findings indicate that without using a tool-based strategy, current LLMs are unsuitable for standalone use even on minimally complex administrative tasks in clinical settings,” says Benjamin Glicksberg. “Structured data tasks in clinical workflows will require agentic approaches that combine LLMs with code execution to ensure accuracy and consistency.”
Half of answers to evidence based questions “somewhat” or “highly” problematic
A substantial amount of medical information provided by 5 popular chatbots is inaccurate and incomplete, with half of the answers to clear evidence based questions “somewhat” or “highly” problematic, show the results of a study published in the open access journal BMJ Open.
Continued deployment of these chatbots without public education and oversight risks amplifying misinformation, warn the researchers.
Generative AI chatbots have been rapidly adopted across research, education, business, marketing and medicine, with many people using them like search engines, including for everyday health and medical queries, explain the researchers.
To gauge the level of accuracy provided in areas of health and medicine already prone to misinformation, and therefore with consequences for everyday health behaviour, the researchers probed 5 publicly available and popular generative AI chatbots in February 2025: Gemini (Google); DeepSeek (High-Flyer); Meta AI (Meta); ChatGPT (OpenAI); and Grok (xAI).
Each chatbot was prompted with 10 open ended and closed questions in each of 5 categories of cancer, vaccines, stem cells, nutrition, and athletic performance. The prompts were designed to resemble common ‘information-seeking’ health and medical queries and misinformation tropes online and in academic discourse.
And they were developed to ‘strain’ models towards misinformation or contraindicated advice—a strategy increasingly used for stress testing AI chatbots and picking up behavioural vulnerabilities, note the researchers.
Closed prompts required chatbots to provide pre-defined responses, often with one correct answer, that aligned with the scientific consensus. Open ended prompts typically required chatbots to generate multiple responses in list form.
Responses were categorised as non-, somewhat, or highly problematic, using objective pre-defined criteria. A problematic response was defined as one that could plausibly direct lay users to potentially ineffective treatment or come to harm if followed without professional guidance.
The information was scored for accuracy and completeness, and particular attention was given to whether a chatbot presented a false balance between science and non-science based claims, regardless of the strength of the evidence.
Each response was also graded on readability, ranging from whether it was written in easy, plain English, to difficult, academic language, using the Flesch Reading Ease score.
Half (50%) the responses were problematic: 30% were somewhat, and 20% were highly problematic.
Prompt type was influential: open-ended prompts, for example, produced 40 highly problematic responses—significantly more than expected—and 51 non-problematic responses—significantly fewer than expected. The opposite was true of closed prompts.
While the quality of responses didn’t differ significantly among the 5 chatbots, Grok generated significantly more highly problematic responses than would be expected (29/50; 58%). Gemini generated the fewest highly problematic responses and the most non-problematic ones.
The chatbots performed best in the area of vaccines and cancer, and worst in the area of stem cells, athletic performance, and nutrition.
Answers were consistently expressed with confidence and certainty, with few caveats or disclaimers. Out of the total 250 questions, there were only two refusals to answer, both of which came from Meta AI in response to queries about anabolic steroids and alternative cancer treatments.
Reference quality was poor, with an average completeness score of 40%. Chatbot hallucinations and fabricated citations meant that no chatbot provided a fully accurate reference list.
All readability scores were graded as ‘difficult’, equivalent in complexity to suitability for a college graduate.
The researchers acknowledge that they only assessed 5 chatbots and that commercial AI is rapidly evolving, so their findings might not be universally applicable. And not all real-world queries are deliberately adversarial, an approach they took which may have overstated the prevalence of problematic content.
Nevertheless, “Our findings regarding scientific accuracy, reference quality, and response readability highlight important behavioural limitations and the need to re-evaluate how AI chatbots are deployed in public-facing health and medical communication,” they point out.
“By default, chatbots do not access real-time data but instead generate outputs by inferring statistical patterns from their training data and predicting likely word sequences. They do not reason or weigh evidence, nor are they able to make ethical or value-based judgments,” they explain.
“This behavioural limitation means that chatbots can reproduce authoritative-sounding but potentially flawed responses.”
The data chatbots draw on also includes Q&A forums and social media, and scientific content is typically limited to open access or publicly available articles, which comprise only 30–50% of published studies. While this enhances conversational fluency, it may come at the cost of scientific accuracy, advise the researchers.
“As the use of AI chatbots continues to expand, our data highlight a need for public education, professional training, and regulatory oversight to ensure that generative AI supports, rather than erodes, public health,” they conclude.
Neither radiologists nor multimodal large language models (LLMs) are able to easily distinguish AI-generated “deepfake” X-ray images from authentic ones, according to a study published in Radiology. The findings highlight the potential risks associated with AI-generated X-ray images, along with the need for tools and training to protect the integrity of medical images and prepare health care professionals to detect deepfakes.
The term “deepfake” refers to a video, photo, image or audio recording that appears real but has been created or manipulated using AI.
“Our study demonstrates that these deepfake X-rays are realistic enough to deceive radiologists, the most highly trained medical image specialists, even when they were aware that AI-generated images were present,” said lead study author Mickael Tordjman, MD, post-doctoral fellow, Icahn School of Medicine at Mount Sinai, New York. “This creates a high-stakes vulnerability for fraudulent litigation if, for example, a fabricated fracture could be indistinguishable from a real one. There is also a significant cybersecurity risk if hackers were to gain access to a hospital’s network and inject synthetic images to manipulate patient diagnoses or cause widespread clinical chaos by undermining the fundamental reliability of the digital medical record.”
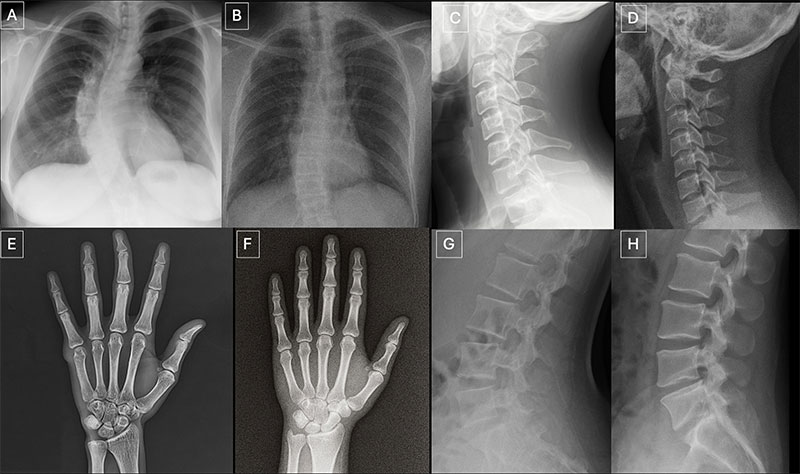
Seventeen radiologists from 12 different centers in six countries (United States, France, Germany, Turkey, United Kingdom and United Arab Emirates) participated in the retrospective study. Their professional experience ranged from 0 to 40 years. Half of the 264 X-ray images in the study were authentic, and the other half were generated by AI. Radiologists were evaluated on two distinct image sets, with no overlapping between the datasets. The first dataset included real and ChatGPT-generated images of multiple anatomical regions. The second dataset included chest X-ray images—half authentic and the other half created by RoentGen, an open-source generative AI diffusion model developed by Stanford Medicine researchers.
When radiologist readers were unaware of the study’s true purpose, yet asked after ranking the technical quality of each ChatGPT image if they noticed anything unusual, only 41% spontaneously identified AI-generated images. After being informed that the dataset contained synthetic images, the radiologists’ mean accuracy in differentiating the real and synthetic X-rays was 75%.
Individual radiologist performance in accurately detecting the ChatGPT-generated images ranged from 58% to 92%. Similarly, the accuracy of four multimodal LLMs—GPT-4o (OpenAI), GPT-5 (OpenAI), Gemini 2.5 Pro (Google), and Llama 4 Maverick (Meta)—ranged from 57% to 85%. Even ChatGPT-4o, the model used to create the deepfakes, was unable to accurately detect all of them, though it identified the most by a considerable margin compared to Google and Meta LLMs.
Radiologist accuracy in detecting the RoentGen synthetic chest X-Rays ranged from 62% to 78% and the LLM models’ performance ranged from 52% to 89%.
There was no correlation between a radiologist’s years of experience and their accuracy in detecting synthetic X-ray images. However, musculoskeletal radiologists demonstrated significantly higher accuracy than other radiology subspecialists.
Spotting the Risks in Synthetic Imaging
“Deepfake medical images often look too perfect,” Dr. Tordjman said. “Bones are overly smooth, spines unnaturally straight, lungs overly symmetrical, blood vessel patterns excessively uniform, and fractures appear unusually clean and consistent, often limited to one side of the bone.”
Recommended solutions to clearly distinguish real and fake images and help prevent tampering include implementing advanced digital safeguards, such as invisible watermarks that embed ownership or identity data directly into the images and automatically attaching technologist-linked cryptographic signatures when the images are captured.
“We are potentially only seeing the tip of the iceberg,” Dr. Tordjman said. “The logical next step in this evolution is AI-generation of synthetic 3D images, such as CT and MRI. Establishing educational datasets and detection tools now is critical.”
The study’s authors have published a curated deepfake dataset with interactive quizzes for educational purposes.
Vision-enabled artificial intelligence (AI) medical scribes could increase the accuracy of patient notes and save valuable time for clinicians
The introduction of vision-enabled artificial intelligence (AI) to medical scribes – the recording devices used by doctors to document meetings with patients in real-time – could increase the accuracy of patient notes and save valuable time for clinicians.
A Flinders University study, published in npj Digital Medicine, has found that AI medical scribes already reduce some administrative work that takes time away from patients, but these devices have the capacity to do more when fitted with visual recording apparatus.
Researchers from Flinders’ College of Medicine and Public Health found that a vision-enabled AI scribe, employing a combination of Google’s Gemini model and Ray-Ban Meta smart glasses, substantially improved the documentation accuracy of pharmacist-patient consultations and reduced omissions and errors in clinical notes.
“AI scribes are already helping clinicians by listening to consultations, but healthcare involves far more than spoken words,” says research author Bradley Menz, an academic pharmacist in Flinders’ College of Medicine and Public Health.
“A lot of clinically important information is visual. Important visual cues during consultations include patients’ medicine containers, prescriptions and devices, as well as their body language. When an AI system can use both what it hears and what sees in these consultations, it captures more of the details that matter for patient care.”
In the study, 10 clinical pharmacists recorded 110 ‘mock’ medication-history interviews, which contained more than 100 different medicine containers, including tablets, capsules, injections and creams.
Researchers wore Meta AI Ray-Ban glasses to record the interview before passing the video footage through to the AI scribe, which was developed using Google’s Gemini AI model.
An AI scribe that analysed both video and audio achieved 98% accuracy, compared with 81 per cent when the same system processed only audio information.
A significant benefit was capturing medication strength and form, which are crucial details for safe dosing. The AI scribe with video input captured this information 97% of the time, while audio-only recordings fell to 28%.
“This is an augmented tool, not a replacement for clinical judgement,” says Mr Menz. “The clinician still needs to review and sign off the document.
“The AI scribe can contain a verification step, take screenshots of medication packages, and generate a full spoken transcript, giving the health professional a much stronger basis for checking what the AI has produced.”
“AI scribes have gained traction because they reduce the burden of documentation and give clinicians more time with their patients. These findings suggest that the next step – when the scribe can see as well as hear – produces a more accurate and complete draft,” says Associate Professor Hopkins. “This means less time editing AI-documentation and even more time focusing on patient care.
“These findings suggest the next step may be that all scribe systems can interpret visual information as well as speech, which could open the door to wider clinical uses.”
The authors say the study has some limitation and underlines the need for human oversight and careful governance before these tools are adopted more broadly. The paper also highlights privacy, consent, data security and workflow integration as important issues that will need to be addressed as vision-enabled AI scribes move closer to practice.
By Kerissa Varma, Microsoft Chief Security Advisor, Africa
Africa’s healthcare sector is facing a silent emergency. Many healthcare operators, facilities and doctors across Africa already grapple with the challenges of under-resourced environments, an uneven distribution of resources and massive demand for services. Now, healthcare administrators must turn their attention to a relatively new and extremely urgent concern. While doctors fight to save lives, cybercriminals are infiltrating hospitals, laboratories, and clinics, turning life-saving environments into digital battlegrounds.
A growing epidemic
World Health Organization director-general Tedros Adhanom Ghebreyesus noted that the digital transformation of healthcare, combined with the high value of health data, has made the sector a prime target for cybercriminals, commenting that “At best, these attacks cause disruption and financial loss. At worst, they undermine trust in the health systems on which people depend, and even cause patient harm and death.”
Recent attacks have exposed the fragility of Africa’s medical infrastructure. In May 2025, Mediclinic Southern Africa was hit by a cyber extortion attack, compromising sensitive HR data. Later in 2025, Lancet Laboratories faced a regulatory penalty for failing to notify patients about data breaches under South Africa’s POPIA law, while a ransomware strike on the National Health Laboratory Service disrupted blood test processing nationwide, delaying critical care for millions.
M-Tiba, a Kenyan digital health platform managed by CarePay and backed by Safaricom, suffered a significant cyberattack and data breach in late 2025, while earlier this year Pharmacie.ma, a Moroccan pharmaceutical platform, was reportedly the target of an alleged data leak incident that allegedly involved the unauthorised export of a customer database. And recent research indicates that Nigeria’s private healthcare sector is now one of the most targeted on the African continent, with attacks increasing at an alarming rate.
Many incidents also go unreported, as hospitals and healthcare facilities rarely disclose them publicly, yet these incidents are not isolated, with ransomware dominating the threat landscape. Africa’s healthcare sector is heavily targeted by cybercriminals, with healthcare organisations facing an average of 3575 weekly attacks in 2025, a 38% surge from the previous year, with encryption of patient data, temporary loss of access to hospital systems and the risk of data appearing on the dark web cited as potential impacts.
Why healthcare is a prime target
The healthcare industry in Africa, particularly in the public sector, is working with legacy systems, fragmented infrastructure, and underfunded IT teams, all of which combine to make the sector an easy target for unscrupulous bad actors.
Many medical institutions are adopting open-source AI tools for diagnostics and patient management. While cost-effective, these platforms often lack enterprise-grade security, leaving sensitive data exposed. Combined with fragmented storage of paper and electronic patient records – often unencrypted and scattered across multiple systems – the risk of breaches multiplies.
Hospitals and healthcare facilities cannot afford downtime. Every minute offline risks lives, making them more likely to pay ransoms in an attempt to regain control of their systems. Cyber insurers indicate that in 2 of 5 cases of a ransom being paid, data and operations still cannot be recovered. Additionally, in instances where some or all of the seized data is recovered after paying a ransom, the attacker goes on to request further payments.
Medical records are also a premium target for cybercriminals. In the USA, researchers found that patient records, insurance details, and research data fetch premium prices on the dark web – up to 10 times higher than financial data, according to cybersecurity analysts. A single stolen medical record can sell for $260–$310, compared to $30–$50 for a credit card, because unlike credit cards, medical records never expire and medical information cannot be easily changed, making it useful for years. Medical records frequently include personal identifiers, insurance details, and sometimes biometric data, enabling identity theft and fraud, while criminals use medical data for fake insurance claims, prescription fraud, and targeted scams. Microsoft believes cybersecurity needs to be embedded into every technology implementation. This should be a key priority, especially with sensitive medical data and operations.
How healthcare can use modern technology safely
As Africa’s healthcare systems digitise and embrace AI, protecting the digital lifeline must become as critical as protecting the physical one. Key steps can secure healthcare organisations and facilities like laboratories and diagnostic services’ systems.
Include cybersecurity in your resilience planning
Medical professionals and healthcare facilities often prioritise the resilience of physical capabilities. Power backups, multiple devices should equipment fail, and a standby roster in the event of a practitioner being unavailable are all practices that save lives. Equally cybersecurity and safeguarding online systems needs to be built into the overall resilience planning of medical facilities and services.
Investing in cybersecurity technology that can quickly identify and contain attacker activity before it leads to system downtime or data theft can save lives. Having a response plan that is practiced and maintained in the event of a cyber breach and ensuring strong data backups could mean the difference between a total failure of health services or a minor incident. Ensuring incident response plans are aligned with local compliance laws such as South Africa’s POPIA, and Kenya and Nigeria’s Data Protection Acts is critical for healthcare providers to meet both their resilience and compliance objectives.
Prepare for AI-driven attacks that are going to increase attacker speed and success
Threat actors are increasingly exploiting the interconnectedness of modern software ecosystems and operational structures to conduct malicious activity, so regular auditing of third-party integrations, especially those involving AI or cloud services, is critical.
Adversaries are using AI to scale and tailor operations, with AI-driven phishing being 4.5x more effective than traditional phishing. However, in equal measure, AI is transforming cyber defence – it automates response and containment, detects threats faster and more accurately, and identifies detection gaps and adapts to attacker behaviour. Healthcare organisations should invest in AI-driven threat detection for faster response and anomaly detection and must also take steps to secure AI models and data pipelines by implementing robust access controls, vulnerability scanning, and regular patching for open-source tools.
Remote and wider access to patient records requires strong identity practices
As both patients and medical professionals start accessing patient records digitally, strong means of identification, verification and authentication are critical. The Microsoft Digital Defense Report 2025 notes that the abuse of valid accounts is a frequent occurrence, with malicious actors gaining access to user credentials (usernames and passwords) and using them to infiltrate systems without triggering traditional security alerts. Therefore, organisations must deploy phishing-resistant multifactor authentication (MFA) and conditional access to strengthen user defences.
Invest in people and skills
People are at the heart of robust cybersecurity measures, so it is vital to train staff against common tactics such as phishing, which is the most common entry point for attackers, and apply role-based access controls for both clinical and research data to prevent privilege misuse.
Cybersecurity is no longer an IT issue – it’s a patient safety issue. Healthcare services and providers must treat digital resilience with the same urgency as infection control. By investing in comprehensive cybersecurity strategies and leveraging AI-powered defences, Africa’s healthcare sector can position itself as a crucial front line against emerging threats and help build stronger, more resilient digital ecosystems.
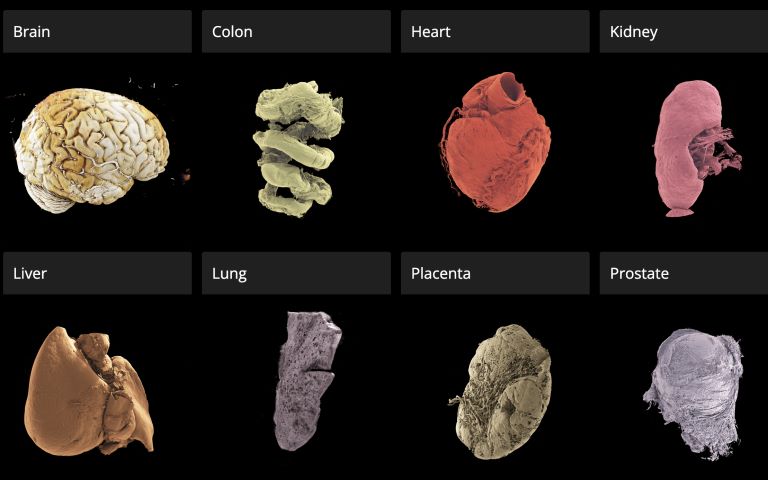
A new open-access 3D portal that allows users to explore human organs in unprecedented detail, from the whole organ to individual cells, has been launched by an international team led by UCL scientists.
The Human Organ Atlas, described in a new paper in the journal Science Advances, brings together some of the most detailed images of 3D organs ever produced. It enables scientists, doctors, educators, students and the wider public to interactively “fly through” organs such as the brain, heart, lungs, kidney and liver, providing a new way of understanding human anatomy and human diseases.
The resource can be accessed directly through a standard web browser, without specialist software, at this link.
The Atlas is powered by an advanced X-ray imaging method called Hierarchical Phase-Contrast Tomography (HiP-CT), developed at the European Synchrotron (ESRF) in Grenoble, France. HiP-CT uses the ESRF’s Extremely Brilliant Source – a new generation of synchrotron source – which is up to 100 billion times brighter than conventional hospital CT scanners.
This allows researchers to scan entire intact ex vivo human organs (i.e., donated organs) non-destructively and then zoom in to near-cellular resolution (down to less than one micron, 50 times thinner than the size of a human hair).
The technique bridges a century-old gap in medicine between radiology and histology, and represents a major advance in biomedical imaging.
Professor Peter Lee (UCL Department of Mechanical Engineering), principal investigator of the Human Organ Atlas beamtime, said: “To create the Human Organ Atlas, we brought together scientists and medics from nine institutes worldwide. This grouping is continuing to expand, helping gain new insights into diseases from osteoarthritis to heart disease and changing how we learn about the human body.”
Dr Claire Walsh (UCL Department of Mechanical Engineering), Director of the Human Organ Atlas Hub, said: “The Human Organ Atlas shows what team science can achieve at its best – we went into this project wanting this data to be used by others and to help further the understanding of human physiology. The Human Organ Atlas is an incredible resource that will continue to grow. I am personally hugely excited to see how the AI community use the Human Organ Atlas in AI foundation models.”
From Covid-19 to cardiac and gynaecological disorders
Professor Judith Huirne, based at Amsterdam UMC, said: “The virtual 3D histological data derived from Human Organ Atlas hub provides us with valuable insights into the pathogenesis of gynecological disorders. This knowledge is crucial to bridging the current gaps in both understanding and gender disparities.”
This Human Organ Atlas portal is the result of more than five years of collaborative effort betweenmany researchers, engineers, clinicians, and infrastructure specialists, united within the Human Organ Atlas Hub, a consortium involving nine institutes across Europe and the United States.
Since its inception, the team has been committed to open science. Dr Paul Tafforeau, ESRF scientist and pioneer of the imaging technique used to create the Human Organ Atlas, said: “From the beginning, we wanted these data to be accessible to everyone and build an open, shared scientific infrastructure at a global scale. This is a resource for researchers, doctors, educators – but also for anyone curious about how the human body is built.
A unique tool for AI, medicine and education
To the team’s knowledge, this is the highest-resolution open 3D dataset of intact human organs currently available. The Human Organ Atlas currently provides access to: (to be updated)
62 organs, 319 full 3D datasets from 29 donors
12 organ types, including brain, heart, lung, kidney, liver, colon, eye, spleen, placenta, uterus, prostate and testis
Multiscale scans, from whole-organ views down to near-cellular resolution (routinely down to 2 µm, as fine as 0.65 microns for some organs)
The portal has been designed to extend far beyond specialist research laboratories. Each dataset can reach hundreds of gigabytes or even over a terabyte in size. The largest one (a brain) is 14 Tb. To make the data usable worldwide, the portal provides:
Interactive browser-based visualisation (no special software required)
Downloadable datasets at multiple resolutions
Tutorials and software tools for analysis
Regular addition of new data
Beyond advancing anatomical and biomedical research, the atlas is expected to become a major resource for artificial intelligence. Large, high-quality 3D datasets are rare – limiting the development of advanced medical AI systems. The Human Organ Atlas provides a curated, hierarchical dataset ideally suited for training machine-learning models for segmentation, disease detection and super-resolution analysis.
At the same time, it offers powerful new opportunities for medical education and public engagement with science, allowing anyone to explore the human body out of curiosity.
Small cell lung cancer cells (green and blue) that metastasised to the brain in a laboratory mouse recruit brain cells called astrocytes (red) for their protection. Credit: Fangfei Qu
Artificial intelligence tools are increasingly being developed to predict cancer biology directly from microscope images, promising faster diagnoses and cheaper testing. But new research from the University of Warwick, published in Nature Biomedical Engineering, suggests that many of these systems may be using visual shortcuts rather than true biology – raising concerns that some AI pathology tools are currently too unreliable for real-world patient care.
“It’s a bit like judging a restaurant’s quality by the queue of people waiting to get in: it’s a useful shortcut, but it’s not a direct measure of what’s happening in the kitchen,” says Dr Fayyaz Minhas, Associate Professor and principal investigator of the Predictive Systems in Biomedicine (PRISM) Lab in the Department of Computer Science, University of Warwick, and lead author of the study.
“Many AI pathology models are doing the same thing, relying on correlations between biomarkers or on obvious tissue features, rather than isolating biomarker-specific signals. And when conditions change, these shortcuts often fall apart.”
To reach this conclusion, the researchers analysed more than 8000 patient samples across four major cancer types – breast, colorectal, lung and endometrial – and compared the performance of leading machine learning approaches. While the models often achieved high headline accuracy, the team found this frequently came from statistical “shortcuts.”
For example, instead of detecting mutations in the cancer-associated BRAF gene, a model might learn that BRAF mutations often occur alongside another clinical feature such as microsatellite instability (MSI). The system then learns to use this combination of cues to predict BRAF status rather than learning the causal BRAF signal itself – meaning accurate cancer predictions work only when these biomarkers co-occur and become unreliable when they do not.
Kim Branson, SVP Global Head of Artificial Intelligence and Machine Learning, GSK and co-author says, “We’ve found that predicting a BRAF mutation by looking at correlated features like MSI is often like predicting rain by looking at umbrellas – it works, but it doesn’t mean you understand meteorology.
“Crucially, if a model cannot demonstrate information gain above a simple pathologist-assigned grade, we haven’t advanced the field; we’ve just automated a shortcut. The roadmap for the next generation of pathology AI isn’t necessarily bigger models; it’s stricter evaluation protocols that force algorithms to stop cheating and learn the hard biology.”
When performance of AI models was assessed within stratified patient subgroups, such as only high-grade breast cancers or only MSI-positive tumours, accuracy fell substantially, revealing that the models were dependent on shortcut signals that disappear once confounding factors are controlled.
For certain prediction tasks, the performance advantage of deep learning over human-derived clinical information was modest. AI systems achieved accuracy scores of just over 80% when predicting biomarkers, compared with around 75% using tumour grade alone – a measure already assessed by pathologists.
Machine learning methods can still prove valuable for research, drug development candidate screening and for clinical triaging, screening, or supplementary decision support. However, the researchers argue that future AI tools must move beyond correlation-based learning and adopt approaches that explicitly model biological relationships and causal structure.
They also call for stronger evaluation standards, including subgroup testing and comparison against simple clinical baselines, before looking at deployment in routine care.
Dr Minhas concludes, “This research is not a condemnation of AI in pathology. It is a wake-up call. Current models may perform well in controlled settings but rely on statistical shortcuts rather than genuine biological understanding. Until more robust evaluation standards are in place, these tools should not be seen as replacements for molecular testing, and it is essential that clinicians and researchers understand their limitations and use them with appropriate caution.”
Researcher demo-ing an early prototype of the robotic medical crash cart. Credit: Cornell Tech
Healthcare workers have an intense workload and often experience mental distress during resuscitation and other critical care procedures. Although researchers have studied whether robots can support human teams in other high-stakes, high-risk settings such as disaster response and military operations, the role of robots in emergency medicine has not been explored.
Enter Angelique Taylor, the Andrew H. and Ann R. Tisch Assistant Professor at Cornell Tech and the Cornell Ann S. Bowers College of Computing and Information Science. She is also an assistant professor in emergency medicine at Weill Cornell Medicine and director of the Artificial Intelligence and Robotics Lab (AIRLab) at Cornell Tech.
In a pair of articles published at the Institute of Electrical and Electronics Engineers (IEEE) conference on Robot and Human Interactive Communication (RO-MAN) in August 2025, Taylor and her collaborators at Weill Cornell Medicine, associate professor Kevin Ching and assistant professor Jonathan St. George, described research on their new robotic crash cart (RCC) — a robotic version of the mobile drawer unit that holds supplies and equipment needed for a range of medical procedures.
“Healthcare workers may not know or may forget where all the various supplies are located in the cart drawers, and often they’re kind of shuffling through the cart,” Taylor said. This can cause delays during emergency procedures that require iterative tasks with precise timing, exacerbating medical errors and putting patients at risk, she noted.
To create the RCC, Taylor and her team outfitted a standard cart with LED light strips, a speaker, and a touchscreen tablet integrated with the Robot Operating System. This middleware connects computer programs to robot hardware, enabling them to work together to provide users with verbal and nonverbal cues.
During an emergency procedure, a user can request the location of a supply on the tablet. Then the lights around the drawer with that supply blink, or a spoken instruction plays through the speaker. Users can also receive prompts to remind them about necessary medications and recommend supplies.
In their article, “Help or Hindrance: Understanding the Impact of Robot Communication in Action Teams,” Taylor’s team conducted pilot studies of the RCC. One pilot involved 84 participants, aged 21 to 79, about half of whom had a clinical background. Working in groups of 3 to 4, they conducted a series of simulated resuscitation procedures with a manikin patient using three different carts: a RCC with blinking lights for object search and spoken task reminders, a RCC with blinking lights for task reminders and spoken language for object search, or a standard cart.
The team found that participants preferred the RCC that provided verbal and nonverbal cues over no cues with the standard cart — rating it lower in terms of workload and higher in usefulness and ease of use.
“These results were exciting and achieved statistical significance, suggesting that the use of a robot is beneficial,” said Taylor. The article, by Taylor, Ph.D. student Tauhid Tanjim, and colleagues at Weill Cornell, was a Kazuo-Tanie Paper Award finalist, an honor given to the top three papers in their category at the conference.
Similar to the pilot studies, Taylor, along with colleagues at Cornell and Michigan State University, found that the RCC reduced participant workload, depending on whether the robot provided verbal or non-verbal cues. However, they evaluated robots with only one type of cue, not both, and identified room for improvement, particularly in the robot’s visual cues. They are now studying healthcare workers’ impressions of an RCC with multimodal communication.
Taylor hopes that other research teams will start exploring how robots can support healthcare teams in critical care settings. To that end, Taylor and her colleague presented an article at the February 2025 Association for Computing Machinery/IEEE International Conference that offers a toolkit for researchers to build their own RCC.
By Carina Storrs, freelance writer for Cornell Tech.